初见
之前看过黄健宏老师在2014年写的一本《redis设计与实现(第二版)》,作者开篇就介绍了redis几个基本的数据结构,简单动态字符串(SDS),链表,字典,整数集合等等。当时作者在书中对于SDS的结构介绍是这样的:
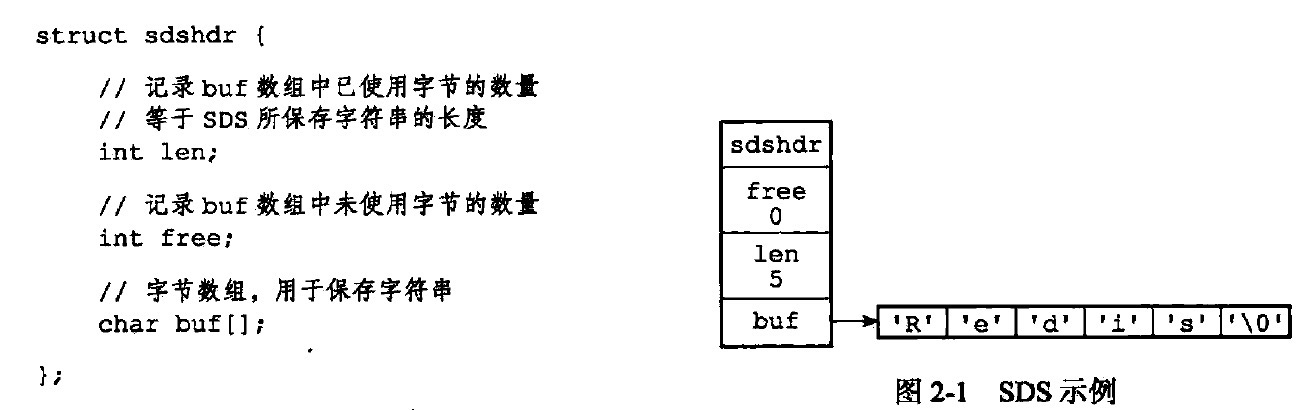
从官网上下载了最新版本的源码来看,发现SDS最新的数据结构已经不是书中的样子了,现在的SDS的结构是这样的
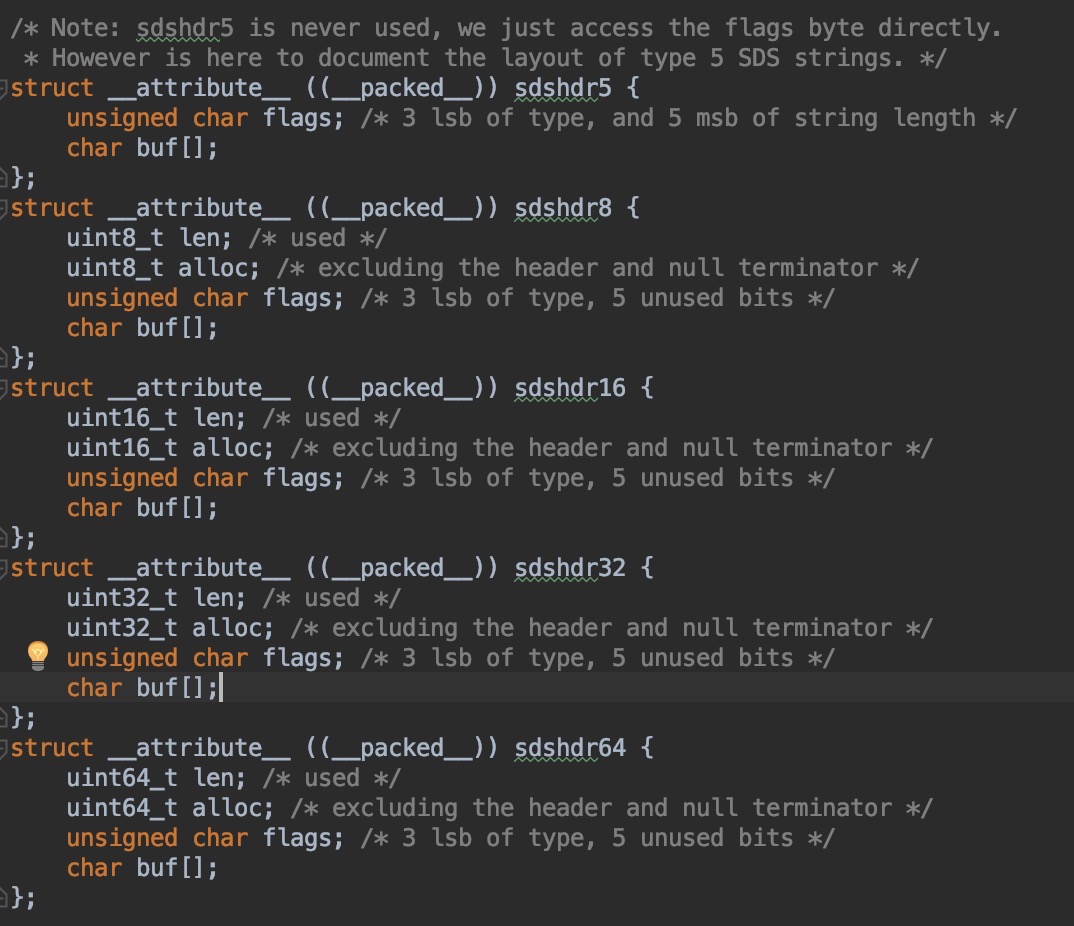
了解了一下原因,发现上述的书籍在出版的时候用的是redis 3.0的版本,而目前最新的版本已经到了5.0,redis在3.2版本之后对于redis的结构设计做了较大的改动。因此就最新的redis源码做一下简单的分析。
数据结构
通过上面两张图的对比可以看到,最新的redis源码对于SDS的数据结构做了较大的调整,从之前统一的一个struct结构体变成了现在的5种不同的数据结构。根据这5种数据结构的名称可以猜测是为了给不同长度的字符串采用不同的数据结构,继续看一下代码来验证我们的猜测对不对。在src/sds.c文件中有这样一个方法
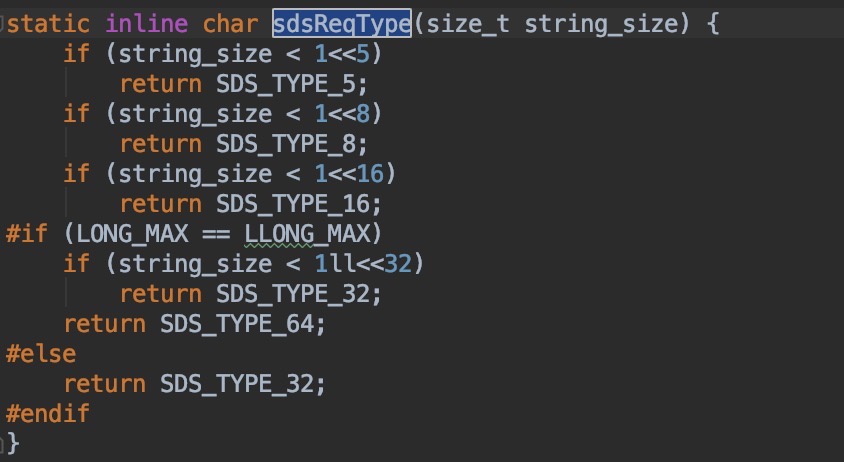
可以看到我们的猜想是正确的,SDS会根据字符串的长度决定采用哪种数据类型。这个方法的传入参数的类型是size_t,size_t的全称应该是size_type,就是说一种用来记录大小的数据类型,size_t的真实类型与操作系统有关,在32位架构中被普遍定义为:
typedef unsigned int size_t;
而在64位架构中被定义为:
typedef unsigned long size_t;
回到图2,我们看一下每个方法中都有__attribute__ ((packed)),那这个是什么意思呢?似乎是设置一个attribute(属性),把这个属性设置为packed,这个属性设置的含义是告诉编译器取消内存对齐优化,按照实际占用的字节数进行对齐,那什么是内存对齐优化呢?先看一下数据对齐的规则:
1.对于结构的各个成员,第一个成员位于偏移为0的位置,以后的每个数据成员的偏移量必须是min(#pragma pack()指定的数,这个数据成员的自身长度)的倍数。
2.在所有的数据成员完成各自对齐之后,结构或联合体本身也要进行对齐,对齐将按照 #pragram pack 指定的数值和结构最大数据成员长度中这两者之中比较小的那个,也就是min(#pragram pack(),长度最长的数据成员,其中#pragram pack(n)表示的是设置n字节对齐,vc6默认的是8。
让我们看下下面一个例子:
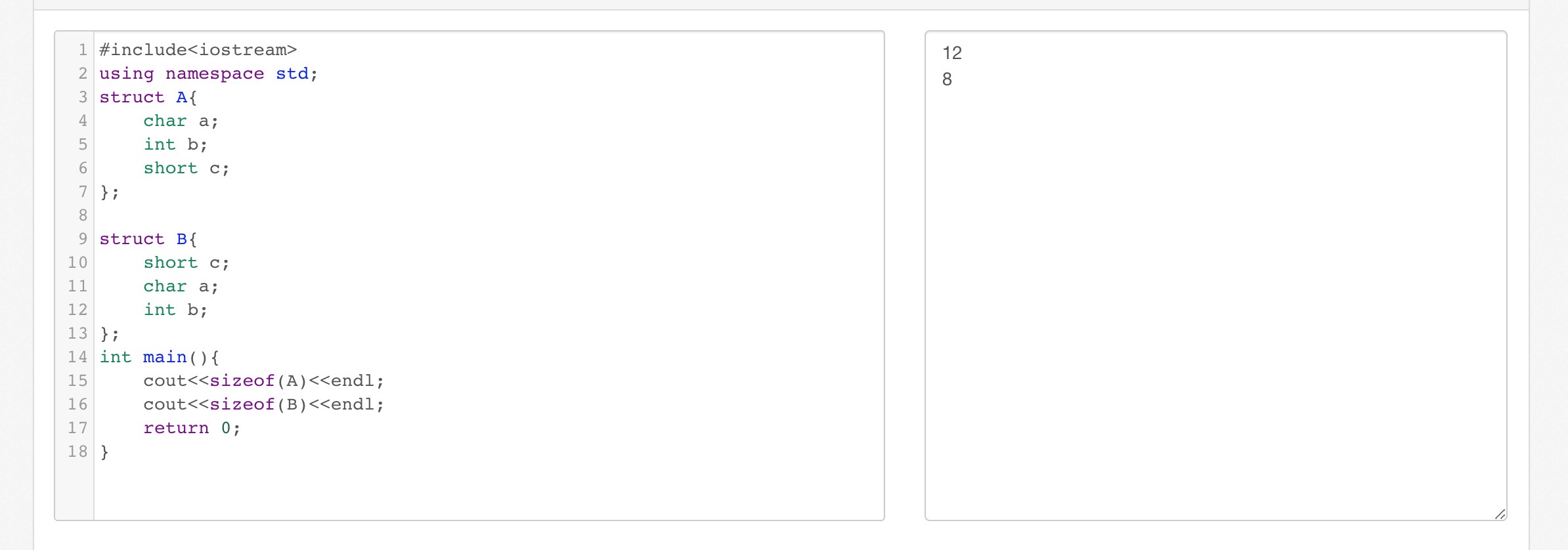
两个结构体A和B,每个结构体的成员都是一个char类型的,一个int类型的,一个short类型的,但是我们看到这两个结构体的大小却不一样,先看struct A。先是一个1字节的char类型,offset为0,接下来是4字节的int类型,这个int类型的偏移量至少是min(4,8)=4,所以应该在char后面加上三个字节,不存放任何东西,short 占两个字节,min(8,2)=2;所以偏移量是2的倍数,而short偏移量是8,是2的倍数,所以无需添加任何字节,所以第一个规则对齐之后内存状态为 1xxx|1111\|11。在完成第一个规则的对齐之后,还有结构体本身的对齐, min(8,4)=4,所以总体应该是4的倍数,所以还需要添加两个字节在最后面,所以内存存储状态变为了 1xxx\|1111\|11xx,一共占据了12个字节。根据上面的陈述可以推出B会占据8个字节。
内存对齐优化的一个好处就是可以提高CPU访问内存的速度,那么redis中设置了__attribute__ ((packed))这个属性之后是不是为了节省内存而放弃了CPU的访问速度呢?当然不是。在src/zmalloc.c中redis自己在C语言的基础上自己封装了malloc分配内存的方法,其中有这样的一句,
if (_n&(sizeof(long)-1)) _n += sizeof(long)-(_n&(sizeof(long)-1));
这个语句的含义是先判断当前要分配的_n个内存是否是long类型的整数倍,如果不是就在_n的基础上加上内存大小差值,从而达到了内存对齐的保证。
我们继续回过头看图3中SDS的数据结构,其中len记录了当前字节数组的长度,这样如果要获取一个字符串的长度的话,时间复杂度从O(n)变成了O(1).
alloc记录了当前字节数组分配的内存大小,这个与len的区别是len是字符串的长度,而alloc是实际分配内存的大小,当字符串大小小于1M的时候会申请两倍的大小,当字符串长度大于等于1M的时候会多分配1M备用。
flags区分了当前字符串的属性,是属于SDS_TYPE_16还是SDS_TYPE_32等等。目前只用了低3位,高5位暂时没有使用。
buf是实际存放内容的数组,和传统字符串一样,是以
\0结尾。
相关方法
创建SDS
我们先看下创建SDS的源码,这部分的源码位于deps/hiredis/sds.c当中
sds sdsnewlen(const void *init, size_t initlen) {
void *sh;
sds s;
char type = sdsReqType(initlen);
/* Empty strings are usually created in order to append. Use type 8
* since type 5 is not good at this. */
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8;
int hdrlen = sdsHdrSize(type);
unsigned char *fp; /* flags pointer. */
sh = s_malloc(hdrlen+initlen+1);
if (sh == NULL) return NULL;
if (!init)
memset(sh, 0, hdrlen+initlen+1);
s = (char*)sh+hdrlen;
fp = ((unsigned char*)s)-1;
switch(type) {
case SDS_TYPE_5: {
*fp = type | (initlen << SDS_TYPE_BITS);
break;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
}
if (initlen && init)
memcpy(s, init, initlen);
s[initlen] = '\0';
return s;
}
从这部分当中我们可以看到SDS_TYPE_5与其他四种SDS数据类型的操作不太一样,回想一下在上一篇当中我们对于SDS数据结构的分析,sdshdr5结构体当中只有buf与flags两个成员,而另外四种数据结构的结构体除了这两个成员之外还有len与alloc,分别记录的是存储的字符串内容的长度以及分配的内存的大小。因为sdshdr5存储的字符数组都在32个字节以下,因此只需要用5bit就能够记录sdshdr5当中字符串的长度,flags这个成员,只用了低三位,而高五位没有用,因此对于sdshdr5来说就可以把需要记录的字符串长度放在flags里面来。而且由于要存储数据比较小,所以没有记录分配的内存大小,这样其他四种数据结构需要4个成员变量,而对于sdshdr5来说只需要使用两个。这样看来,redis在设计数据结构的时候设计的确实很巧妙。
为SDS分配空间
分配内存空间的函数是在src/sds.c当中的sdsMakeRoomFor函数,我们先看下这部分的代码
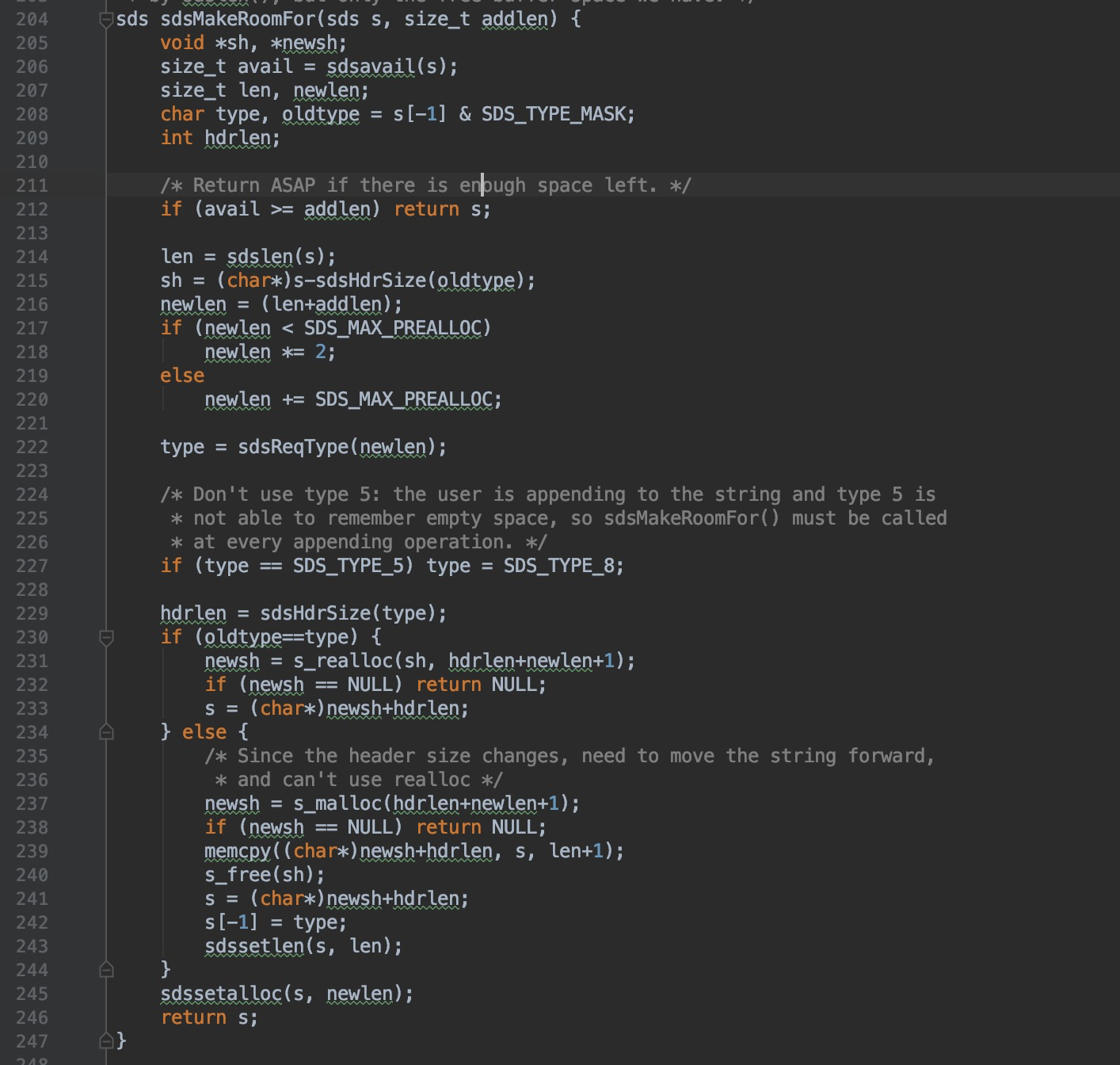
我们看一下217行,在这里我们看到如果分配的内存小于SDS_MAX_PREALLOC,也就是1024*1024=1M,那么就会分配两倍的内存,否则的话就会再多分配1M内存。这样做的好处就是不需要每次进行字符串拼接等操作的时候就要分配内存进行一次操作,内存预分配可以减少操作的次数,提高效率。
我们再看一下227行上面的注释,可以看到对于类型是SDS_TYPE_5的SDS,在这里会把该类型转换为SDS_TYPE_8。因为我们在上面说过对于SDS_TYPE_5,该种数据类型相对于其他数据类型来说结构比较简单,没有记录多余的空间,所以如果要对一个SDS_TYPE_5数据类型进行字符串拼接的话要首先转换一下数据类型。
SDS的惰性释放
从标题的字面意思我们知道是对于不需要的那部分SDS的空间并不会立即释放,比如在对一个字符串进行缩短操作的时候。我们看一下sdstrim函数,这个函数的功能是将cset字符从sds字符串当中去除掉,比如我们执行以下sdstrim(s,”ABC”)就是从字符串s中去掉所有的‘A’,’B’,以及’C’.
基本的数据操作如下图所示
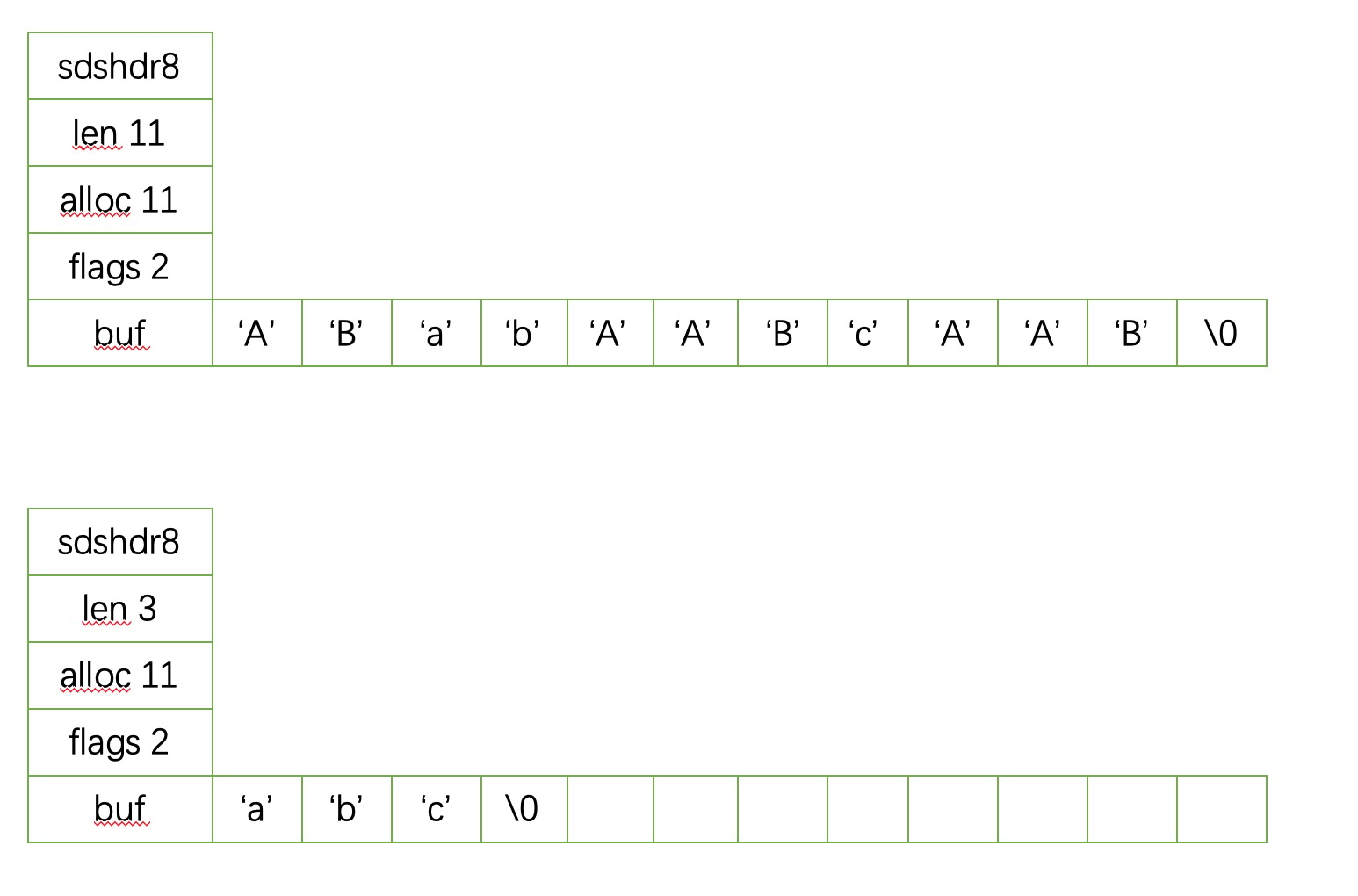
在执行完整个函数之后,SDS并没有立即将alloc当中目前空闲的空间立即释放掉,而是保留这部分空间,留作以后再用。
以上就是对于Redis当中SDS简单动态字符串的简单解析
如果对你有帮助,请作者喝一杯牛奶吧
