数据结构
现在我们来看一下redis压缩列表(ziplist)这种数据结构,这种数据结构的目的是为了节省内存。压缩列表是哈希键以及列表键的底层实现之一, 如果存储的数据是比较小的整数或者是比较短的字符串的话,redis就会使用这种数据结构。ziplist虽然在源码当中像其他数据结构一样有自己的头文件 以及声明函数的c文件,但是并没有像其他数据结构一样有自己的结构体,我们先看一下创建一个新的空白压缩链表的方法
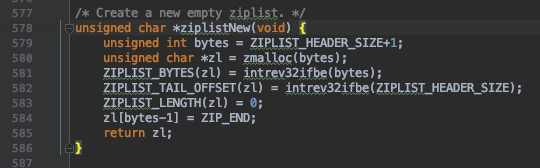
其中ZIPLIST_HEADER_SIZE是这样定义的

这个表示ziplist头部的大小。可以看到头部是由两个uint32_t以及一个uint16_t组成,分别存储总的字节数目,最后一个item的偏移量以及item的数目。 可以看到最后还有一个+1,这个用来存储结束的标志位。其中intrev32ifbe这个函数是进行大小端转换,大端模式就是把数据的高字节保存在内存的低地址当中, 小端模式与之相反。对于每一个节点,zlentry记录会记录节点的信息,代码如下
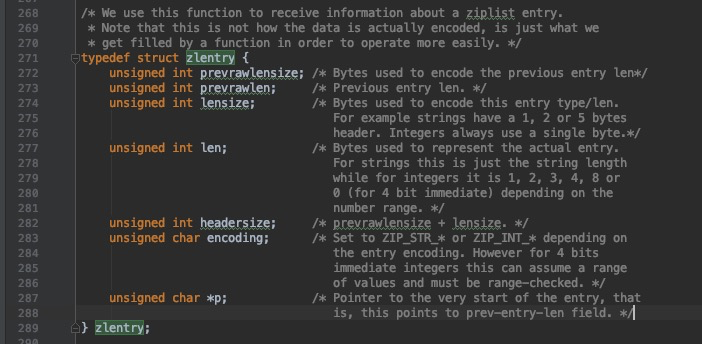
可以看到对于ziplist的每个节点,都会记录前一个节点的信息,prevrawlen记录的是前一个节点的长度,prevrawlensize记录的是前一个节点占用内存的大小。 从这里我们可以了解到压缩链表能够压缩内存的原因,对于一个普通的双向链表来说,除了节点本身要存储的数据外,每一个节点都会存储指向前一个节点的指针以及 指向后一个节点的指针,一共需要8个字节,而通过将上一个节点的数据长度这个数据进行编码之后,所需的内存数目要小于8个字节,而且只需要用当前节点的指针 减去上一个节点长度就可以将指针指向上一个节点,这样就通过存储上一个节点数据大小的方式存储了指向上一个节点的指针。那么对于节点长度这个数据是如何编码 的呢,我们来看一下下面的部分。
encoding会记录节点的编码方式,有ZIP_STR与ZIP_INT两种分类,指针p指向当前节点。下面看一下ziplist的编码方式:
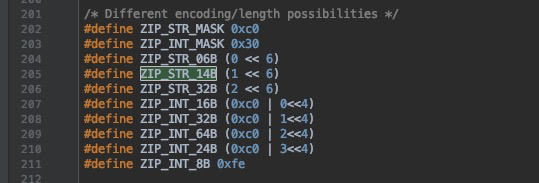
可以看到对于整数以及字节数组有不同的编码方式。下面这个函数的具体含义是检验存储在节点当中的数据能否可以从字符串转化为数字,如果可以的话 会进行相应的编码,转化为对应的数字类型
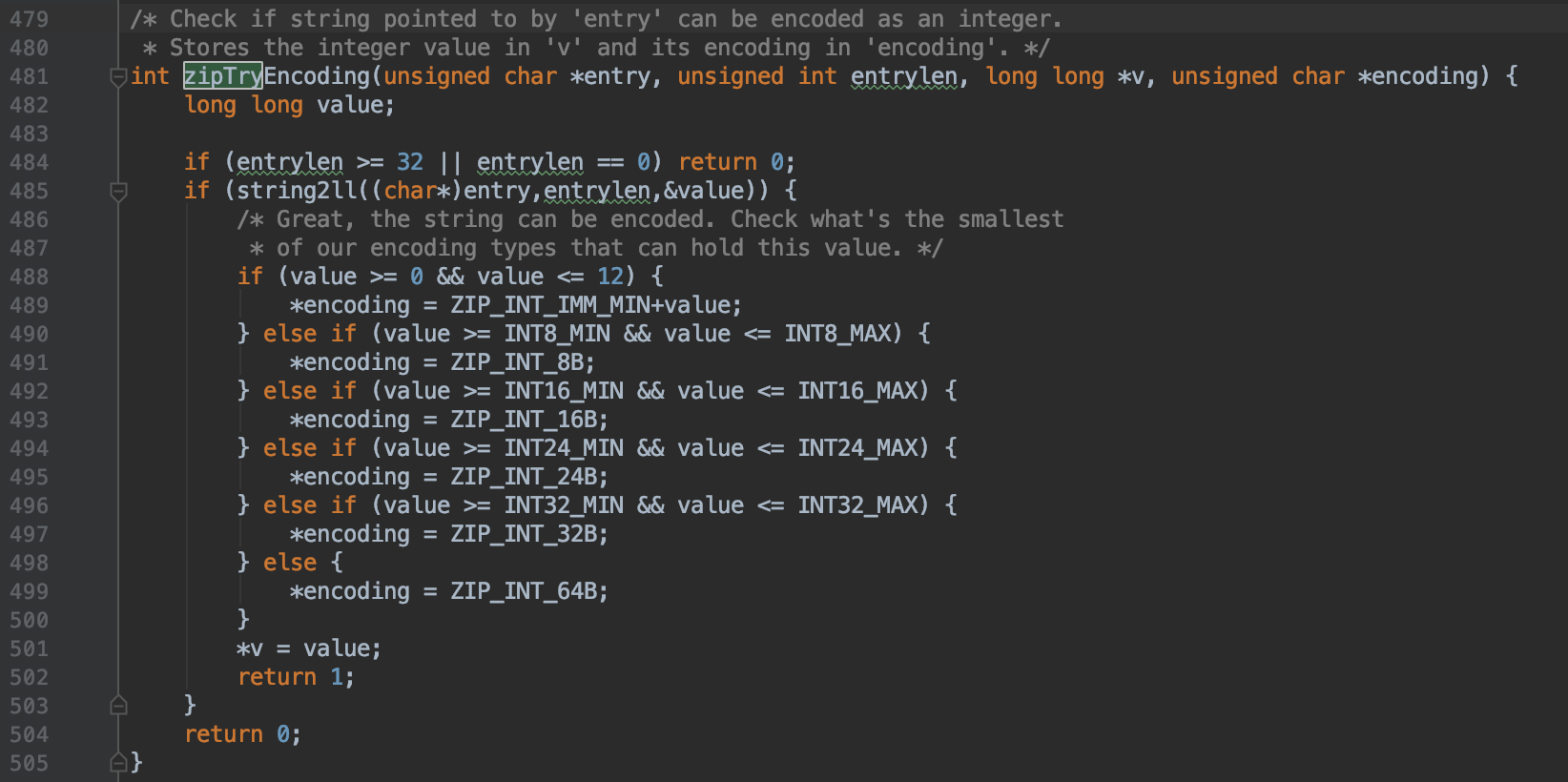
第485行string2ll函数的作用是尝试将一个string类型转化为long long类型的数据,如果能够转化就返回1,否则返回0。如果能够转化为数字类型, 会根据数值的大小进行不同的编码然后存储。INT8_MIN定义如下

_I8_MIN的值是(-127i8 - 1),是最小的有符号位的8位整数,i8表示8位整数。从第488行我们可以看到,如果一个数的数值大小是介于0到12之间的话, 那么编码和数值共同占用一个字节,并不会单独存储value的值。从上面的函数可以看到,对于整数一共有6种编码方式。下面我们通过另外一个函数来看下字 符串的编码类型
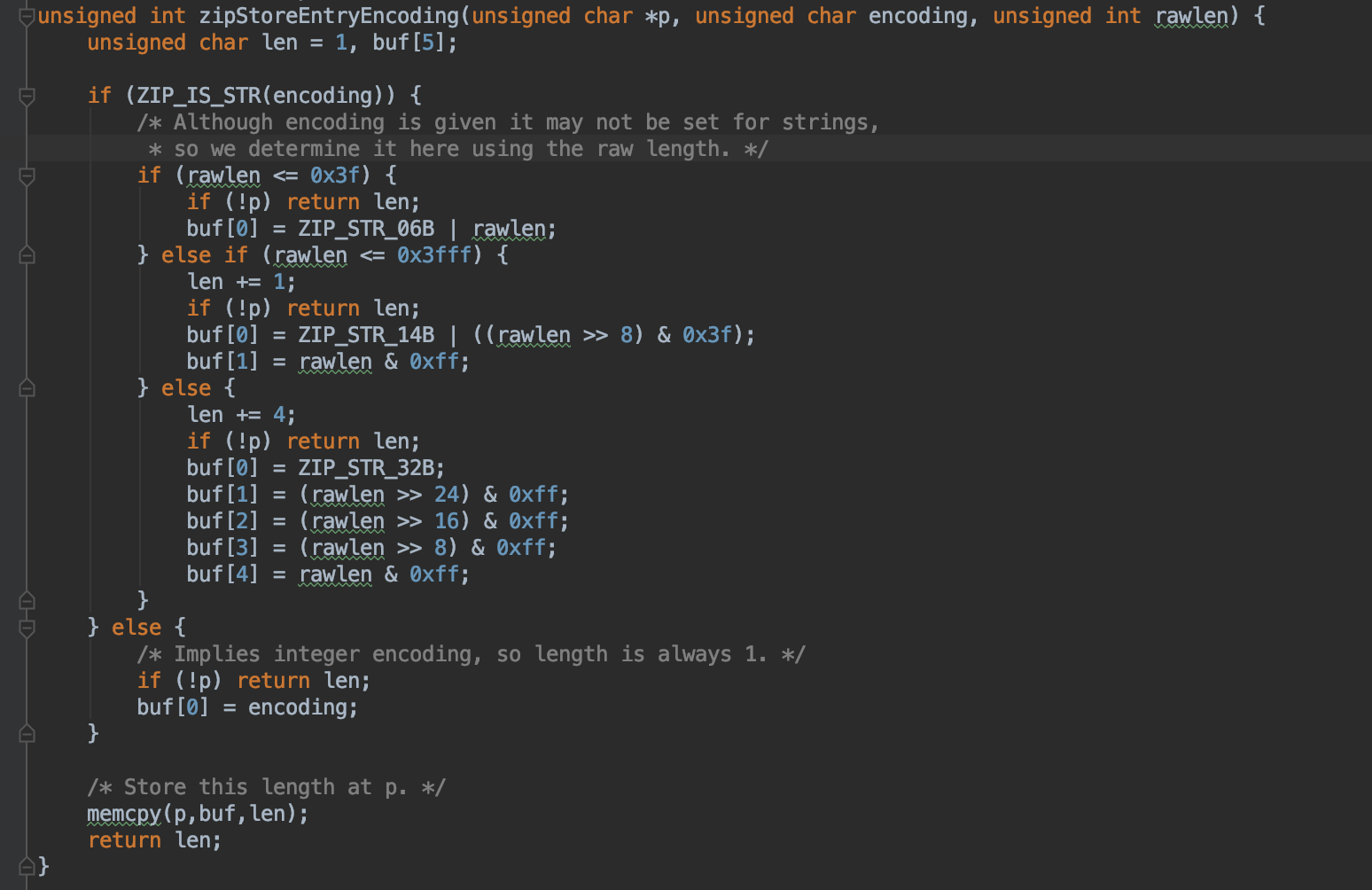
从上面的代码中我们可以看到,对于字符串这种数据类型,根据rawlen的大小,一共有三种不同的编码方式。
我们刚才提到,每一个数据节点中会保存有前一个节点的数据长度,这样会节省内存,但是这样会带来一个问题,也就是连锁更新的问题,前一个节点的长度 小于254字节会用1个字节来存储前一个节点的长度,如果大于254的话会用5个字节。如果增加字节的时候达到了阈值,后面的节点就可能需要扩大,这样后面的 节点也有可能需要用更多字节来存储数据,这就是连锁更新问题,极端情况下可能整个压缩链表都需要进行更新。连锁更新的情况一般发生在链表中节点的长度都 是介于250-253字节之间的,不过这种情况一般比较少见。
以上就是压缩链表的分析。
如果对你有帮助,请作者喝一杯牛奶吧
